
About Me
I am a PhD candidate in Data Science at the University of Virginia School of Data Science, where I am fortunate to work with Dr. Chirag Agarwal in the AIKYAM Lab. My research focuses on Trustworthy AI, with particular emphasis on AI Safety, interpretability, and Multilingual AI. Broadly, I study methods for understanding and monitoring large language models to support scalable oversight, especially when model behavior changes under distribution shift.
Before starting my PhD, I earned an MS in Mathematics from the University of Tennessee at Chattanooga, where I worked with Dr. Lakmali Weerasena on facility location problems in mathematical optimization. I received my bachelor's degree in Mathematics with Economics (First Class Honors) from the University of Cape Coast in Ghana.
Current Research
My current research focuses on interpretability for AI safety, particularly monitoring the reasoning and behavior of large language models, autonomous agents, and multi-agent systems. I investigate how chain-of-thought monitoring and white-box interpretability methods can improve the detection of deceptive, unfaithful, and other misaligned behaviors, as well as multi-agent risks such as collusion, miscoordination, and conflict. My broader goal is to develop reliable monitoring methods for the scalable oversight of increasingly autonomous AI systems and extend these approaches to multilingual AI.
Recent works include:
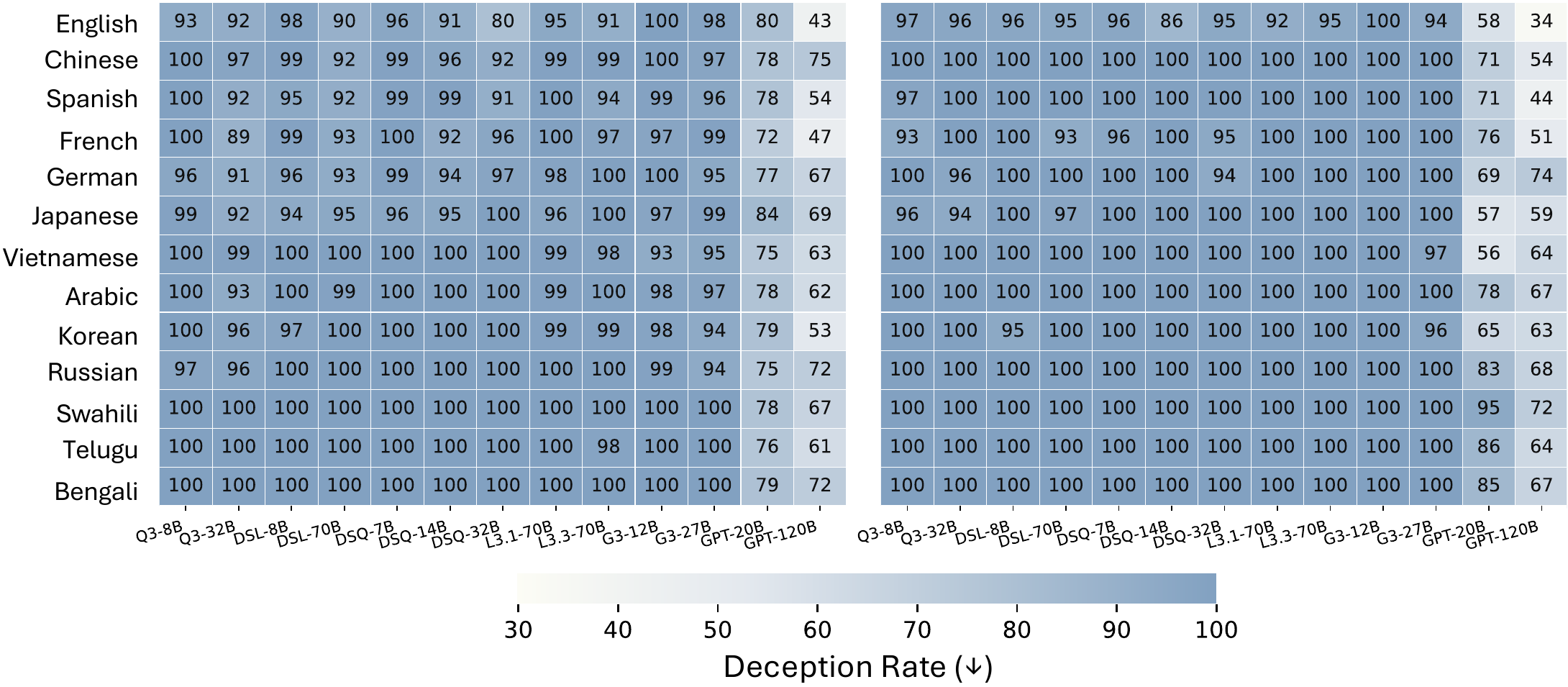
- The Fragility of Chain-of-Thought Monitoring Across Typologically Diverse Languages (arXiv 2026).
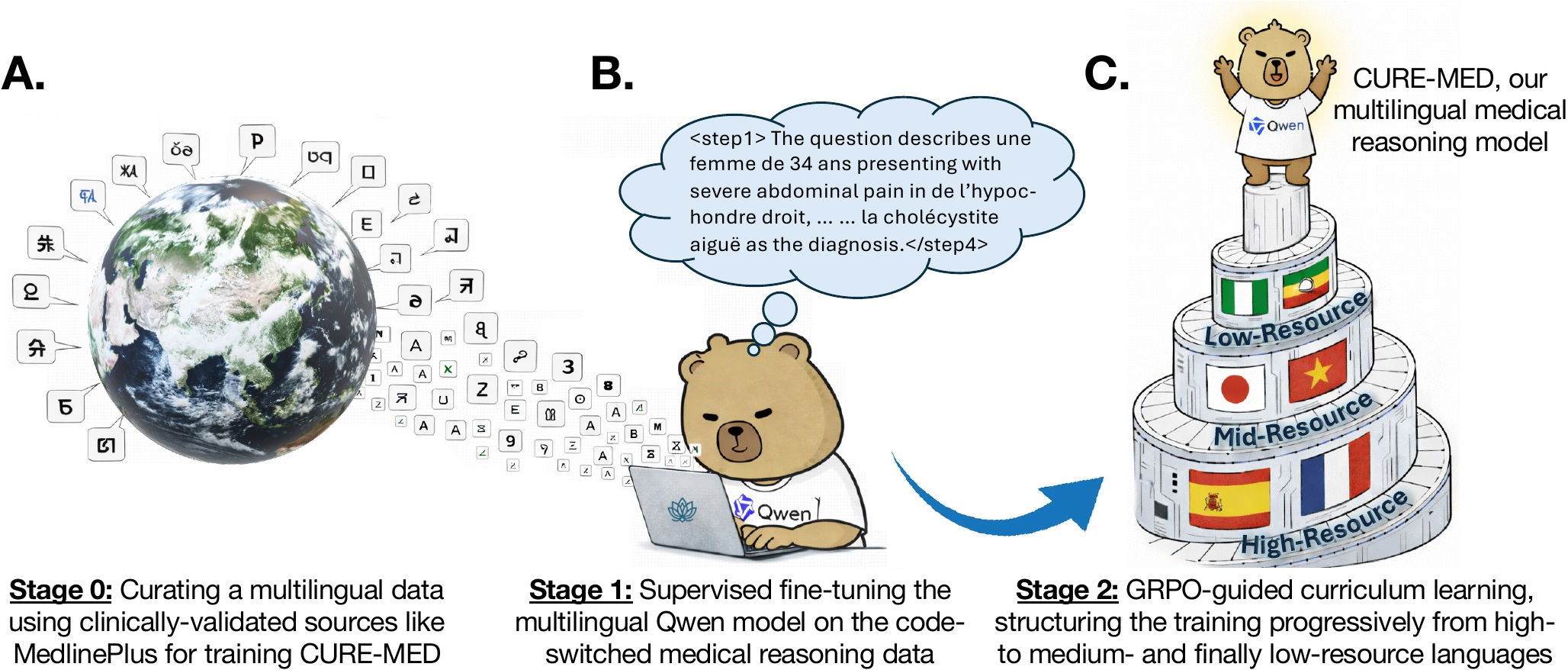
- Curriculum-informed reinforcement learning for multilingual medical reasoning (ACL 2026, Oral).
News
Recent updates and milestones.
Research
I spend most of my time thinking about how to make large language models more reliable, interpretable and aligned with human values. I am broadly interested in Trustworthy AI, with a focus on developing methods for monitoring model behavior, detecting failures and supporting scalable oversight under distribution shift. I am motivated by a central question: how can we build AI systems whose reasoning and outputs remain faithful, safe, and trustworthy across changing tasks, languages, and contexts?
Recently, I have been especially interested in three directions:
How can we monitor the reasoning traces of large language models to better understand when they are faithful, when they fail, and when they may conceal unsafe behavior? I am interested in chain-of-thought monitoring as a tool for scalable oversight, especially for detecting and mitigating unfaithful, deceptive, and scheming behavior in advanced AI systems.
How can we use interpretability methods to understand, evaluate, and improve the safety of AI systems? I study approaches for detecting unsafe or misleading model behavior, with a particular interest in how white-box interpretability methods can make monitoring and oversight more reliable.
How can we build and evaluate models that remain reliable when language, culture, or context changes? I study how model behavior shifts across linguistic settings, with the goal of making AI systems more robust, faithful, and trustworthy for diverse users.
Publications
Selected publications and ongoing work.
Education
Academic journey.
Teaching
Teaching Assistant for core Data Science and AI courses.
Skills
Technical proficiencies.